AI数据服务 去伪存真,打通智能驾驶全场景落地数据闭环
随着智能驾驶技术的飞速发展,数据已成为驱动其演进的核心燃料。海量、多源、异构的原始数据往往掺杂着噪声、错误与无效信息,如同一座未经雕琢的矿山。要实现高级别自动驾驶(L3及以上)的规模化、安全可靠落地,必须构建一个高效、精准、完整的“数据闭环”。这其中,专业化的AI数据服务,特别是以“去伪存真”为核心的数据处理与存储支持服务,正扮演着打通这一闭环、赋能全场景落地的关键角色。
一、 智能驾驶的数据挑战与“数据闭环”必要性
智能驾驶系统在研发、测试与持续优化过程中,需要处理来自激光雷达、摄像头、毫米波雷达、高精地图、车联网(V2X)等多模态的海量数据。这些数据面临三大核心挑战:
- 数据质量参差不齐:存在标注错误、传感器噪声、场景覆盖不全、长尾场景(如极端天气、罕见交通参与者)数据稀缺等问题。
- 数据管理复杂度高:数据量呈指数级增长(单车每日可产生数TB数据),如何高效存储、检索、版本化管理及合规使用成为巨大负担。
- 价值挖掘深度不足:原始数据无法直接用于模型训练,需要经过一系列精细处理才能转化为可驱动算法迭代的“知识”。
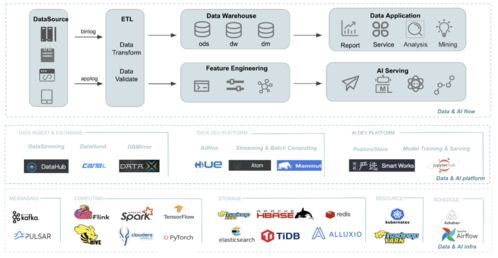
因此,一个理想的“数据闭环”应能自动完成“数据采集 -> 清洗标注 -> 模型训练 -> 仿真测试 -> 车辆部署 -> 问题数据回流”的完整迭代循环。而打通这一闭环的瓶颈,往往在于中间环节——如何将原始、粗糙的“数据原油”提炼成高质量、高价值的“数据汽油”。
二、 “去伪存真”:AI数据服务的核心价值
专业的AI数据服务,正是通过一系列技术与管理手段,实现数据的“去伪存真”,确保输入到算法模型的数据是干净、准确、有用的。
1. 数据清洗与增强:
- 去“伪”:自动识别并过滤传感器失效、传输错误产生的无效帧和噪声数据;通过一致性校验(如多传感器融合校验)剔除矛盾或错误的标注。
- 存“真”与“增”真:对稀缺的长尾场景数据(如交通事故、特殊天气)进行针对性的采集与生成。利用数据增强技术(如GAN生成对抗网络、神经辐射场NeRF),在保证物理真实性的前提下,对现有高质量数据进行扩增,丰富场景多样性。
2. 精准化数据标注:
- 结合自动化预标注工具(如基于现有模型的推理标注)与专业化、多级质检的人工标注,实现效率与精度的平衡。针对3D点云、连续帧视频、语义分割等高难度任务,提供专业化标注服务,确保每一个目标框、每一条车道线、每一个像素都准确无误。
- 建立完善的标注质量管理体系,通过一致性评估、交叉验证等方法,最大限度降低标注误差,保存数据“真值”。
3. 场景化数据管理与洞察:
- 不仅仅是处理,更是理解数据。通过数据挖掘与标签体系,将非结构化的数据转化为结构化的“场景库”(如“雨天-城市路口-行人闯红灯”),便于针对性地检索、分析和使用,让数据背后的真实驾驶场景与挑战清晰浮现。
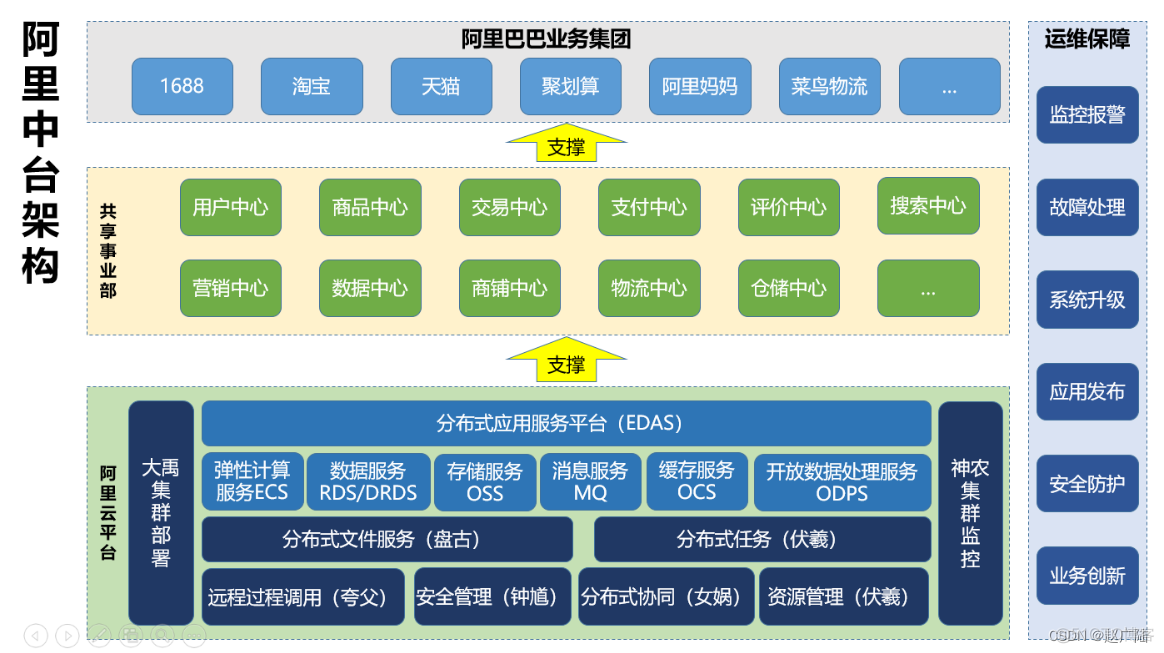
三、 数据处理与存储支持:闭环的稳固基石
高效的数据处理离不开强大、灵活的底层存储与计算支持。专业的数据服务提供商为此构建了关键基础设施:
1. 弹性可扩展的数据湖/仓架构:
- 支持PB级乃至EB级海量原始数据、标注数据、模型数据的低成本、高可靠存储。采用冷热数据分层存储策略,优化存储成本。
- 提供统一的数据目录和元数据管理,实现跨团队、跨阶段的数据资产可见、可查、可用,打破数据孤岛。
2. 高性能数据处理流水线:
- 基于云原生和容器化技术,搭建可并行化、自动化的数据处理流水线。能够快速调度计算资源,完成大规模数据的清洗、标注、转换任务,极大缩短数据准备周期,加速迭代循环。
3. 安全与合规保障:
- 提供数据脱敏、匿名化(如人脸、车牌模糊化)工具与服务,确保数据符合GDPR、中国个人信息保护法等法律法规要求。
- 建立严密的数据权限管理和访问审计机制,保障知识产权与数据安全。
四、 赋能全场景落地
通过“去伪存真”的数据精炼与稳固的数据工程支持,AI数据服务最终赋能智能驾驶在多元化场景中的落地:
- 量产优化:为ADAS(高级驾驶辅助系统)和自动驾驶系统的感知、预测、规划算法提供持续的高质量训练数据,提升系统在高速、城区、泊车等量产场景下的性能与鲁棒性。
- 长尾问题攻克:针对Corner Case(极端案例)进行定向的数据采集、生成与标注,帮助算法补齐短板,提升安全性。
- 仿真测试验证:利用处理后的真实数据构建高保真、多样化的仿真场景库,进行大规模、高风险的虚拟测试,降低实车测试成本与风险。
- 数据驱动迭代:形成“真实问题 -> 数据回流 -> 分析处理 -> 模型再训练”的自动化闭环,使车辆在量产部署后仍能持续进化。
###
在智能驾驶迈向深水区的今天,竞争已不仅是算法模型的比拼,更是数据资产质量与数据闭环效率的较量。专业的AI数据服务,通过“去伪存真”的匠心与坚实的数据处理存储基础设施,将杂乱的原始数据流转化为滋养算法智能的清澈源泉,从而真正打通从技术研发到全场景、规模化安全落地的最后一公里,为智能驾驶的星辰大海之旅保驾护航。
如若转载,请注明出处:http://www.yuanwangyun.com/product/37.html
更新时间:2026-06-19 03:17:37